1. Why we need it?
First lets review what sequence to sequence model does:
We have a fixed length vector C that contains all the information we encoded for input sequence. But you can imagine, as the sequence length gets longer, it is hard for vector C to store all necessary information. So in order to overcome this, we would like to make vector C a sequence vectors; at the same time focus on different part of the necessary information.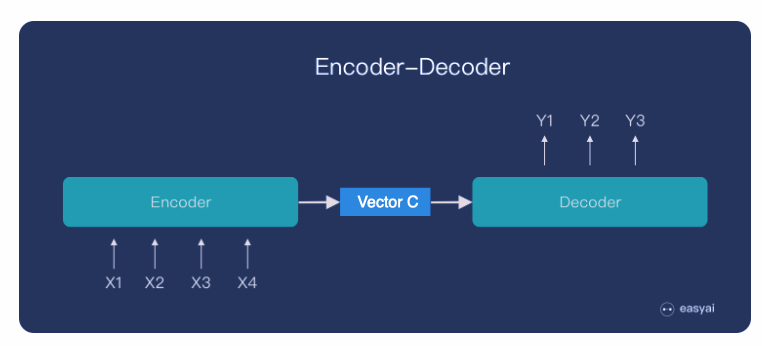
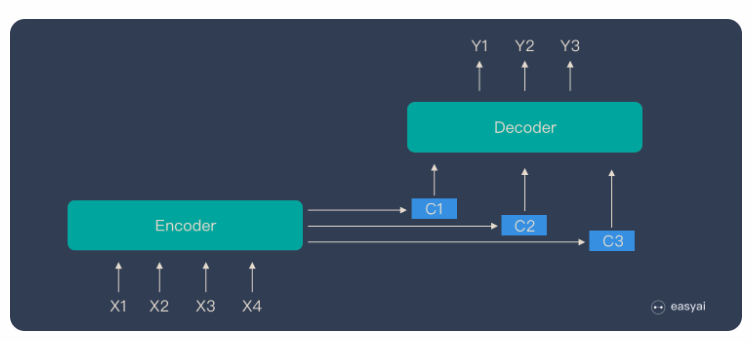
You may argue that LSTM or GRU also has the functionality to remember both the long and short term memory (which is basically the name of LSTM). However to achieve that we need to store lots of different parameters.
However for attention based model we can achieve that without having more parameters.
2. Basic Structure
1) Use bidirectional GRU/LSTM for encoding
2) Instead of one output for each of the sequence, for decoder we build one RNN on top of each unit (like adding one more layer)
3) Use attention weights to get useful information for the encoder
I think among all tutorial materials, professor Hung-yi Lee's make more sense. He made one specific machine translation examples:
The key idea is: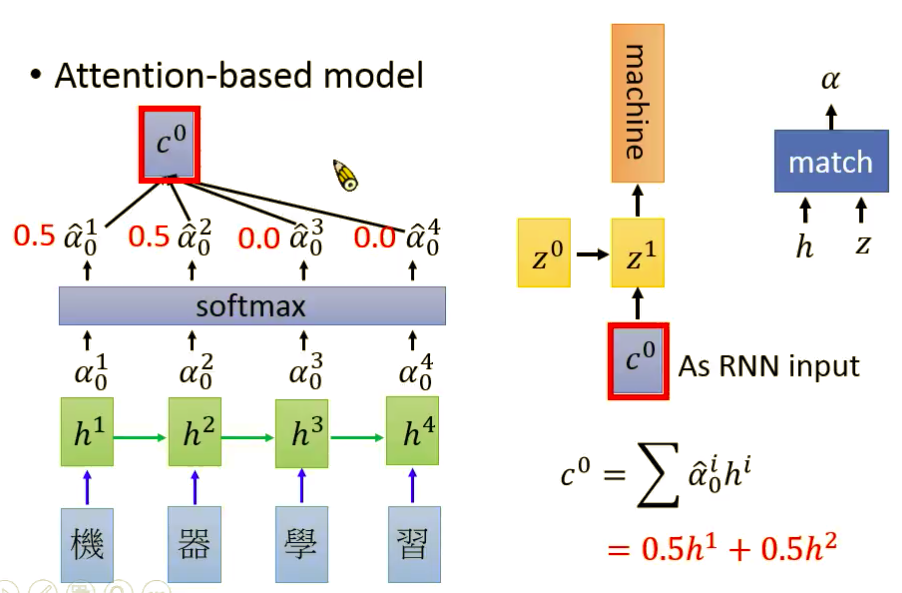
- One vector from the encoder is hard to represent all the information. At the same time, for the input from decoder, we not only want the overall info, but also some focus for only translating this unit
- What we will do is that we calculate the similarities or to say try to find the most relevant input part by using either Cosine similarities or building one simple NN, after that use softmax to standardize this relevance. (Here \(\alpha\) represent the relevance)
- Finally calculate the weighted sum (weight is the relevance parameter \(alpha\) and value is the activations for each hidden layer) as the input for that decoder unit
3. Why works?
Still use back propagation to get the attention weights for each of the unit, but this time we use the weights to tell us which part of the sequence we need to focus on. Comparing with the traditional encoder-decoder model which will take the whole sequence as a whole for the decoder.
Reference:
DeepLearning.ai
http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
https://easyai.tech/ai-definition/encoder-decoder-seq2seq/