Now let's look at some applications of CNN. First one is Neural Style Transfer. Generally speaking, it merges a content image and a style image to create a new image. So this generated image will have the same content with the content image but use the style same with the style image.
The key to achieve this goal is to make clear the following two questions:
- How to get the content of an image
- How to get the style of an image
1. Image Content
1.1 How to get the content of an image
So the idea to know the content of an image is that: suppose we have a pre-trained good CNN like VGG-19, then in some deep layer, we are reasonable to believe that the activation of that layer (The output tensor) is enough to grab the most features of an image. (Encoding of this image)
For example if we pass two images of cats through an CNN, even if the initial images look very different, after being passed through many internal layers, their representations will be very close in raw value.
I think which layer to use is a hyperparameter that need to be decided in different cases. Empirically, we will choose a layer in the middle.
1.2 Content Cost
So the activation value's difference of that layer would be the content cost. Mathematically speaking: \[J_{content}(C,G) = \frac{1}{4 \times n_H \times n_W \times n_C}\sum _{ \text{all entries}} (a^{(C)} - a^{(G)})^2 \]
Here, \(C\) represents the content image and \(G\) represents the image we are generating (We will randomly initialize it first) \(n_H, n_W\) and \(n_C\) are the height, width and number of channels of the hidden layer you have chosen, and appear in a normalization term in the cost. For clarity, note that \(a^{(C)}\) and \(a^{(G)}\) are the volumes corresponding to a hidden layer's activations.
2. Image Style
2.1 How to get the style of an image
The style of an image is a little bit tricky to understand than image content, first let's have a high level definition of the image style:
the style of an image means some kind of features will always appear together. And if we think that the kernels work as feature extractors, then the activation of each channel is just the result of that high level feature! So to get the style of it, we can simply calculate the correlations for the activations in each channel. We use 'Gram Matrix' to quantify that correlation:
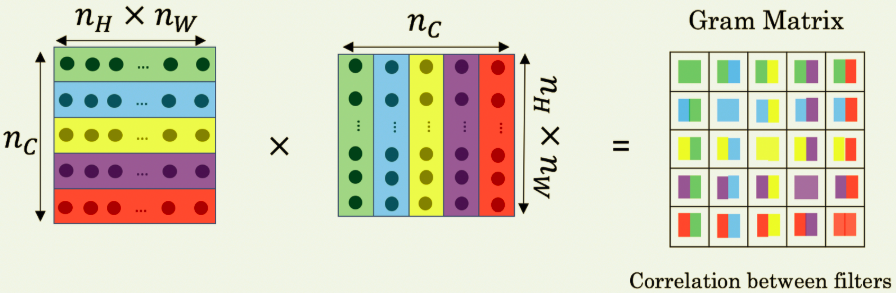
The value \(G_{ij}\) measures how similar the activations of filter \(i\) are to the activations of filter \(j\).
2.2 Style Cost
So the style difference between two images will be the difference between two style matrix:
\[J_{style}^{[l]}(S,G) = \frac{1}{4 \times {n_C}^2 \times (n_H \times n_W)^2} \sum _{i=1}^{n_C}\sum_{j=1}^{n_C}(G^{(S)}_{ij} - G^{(G)}_{ij})^2\]
where \(G^{(S)}\) and \(G^{(G)}\) are respectively the Gram matrices of the "style" image and the "generated" image
3. Summary
So to make a summary about how to create a neural style transferred images, here is the steps:
- Initialize the generated image
- Find a pre-trained CNN
- Feed the content image to one layer of this CNN and get the activation value
- Feed the Style image to one layer of this CNN and get the style matrix value
- Updating generated image to minimize the linear combination cost of Content cost and Style cost
Let's look at some results of my trained model:


Reference: