From previous articles we have already know what is feedforward neural networks and how to improve its performance. But is this architecture works for all type of data?
The answer is no. Suppose we have a fairly small image with size 32x32x3 (32 wide, 32 high, 3 color channels), that means we will have 32x32x3 = 3072 features for our input data, and there is no doubt that we will get a huge number of weights need to be trained as for even deeper hidden layers. Now it comes to Convolution Neural Networks. Convolutional Neural Networks take advantage of the fact that the input consists of images and they constrain the architecture in a more sensible way.
We use three main types of layers to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer.
1. Convolution Layer
Convolution operation is one of the most important breakthrough for deep learning. Basically, it uses a filter with smaller width and height but extends through the full depth of the input volume. We slide (more precisely, convolve) each filter across the width and height of the input volume and compute dot products between the entries of the filter and the input at any position.
1.1 Local Connecting
You see everytime we will connect each neuron to only a local region of the input volume. IThe spatial extent of this connectivity is a hyperparameter called the receptive field of the neuron (equivalently this is the filter size)
How does filter works
Intuition: Each filter can be seen as one type of visual feature of the image such as an edge of some orientation or a blotch of some color on the first layer, or eventually entire honeycomb or wheel-like patterns on higher layers of the network. It works as detector to grab this feature information after convolution.
Parameter Sharing
The reason CNN has much smaller number of parameters is because the parameter sharing scheme. It turns out that we can make one reasonable assumption: The feature detector that is useful in one spatial position is also useful in another part.
1.2 Spatial Arrangement
Padding
Why we need it: we don't want the image to shrink and also the convolution operation will use the data from corner only once. So the nice feature of zero padding is that it will allow us to control the spatial size of the output volumes (most commonly as we’ll see soon we will use it to exactly preserve the spatial size of the input volume so the input and output width and height are the same).Stride
Stride is another hyperparameter to control the spatial size. When the stride is 1 then we move the filters one pixel at a time. When the stride is 2, it will produce smaller output volumes spatially.Depth
It corresponds to the number of filters we would like to use2. Pooling Layer
Pooling layer works similar to Conv layer, but instead of learning the filters, this time we only provide the size of the filter, the stride and it works as an operater to grab the maximum (average and so on) value for each position.
Functionality of Pooling Layer:
- Makes the feature dimension smaller and smaller
- Reduces the number of parameter and computation in the network, therefore control overfitting
- Makes the network invariant to small transformations, distortions and translations in the input images
3. Layer Patterns
The most common form of a ConvNet architecture is like below:
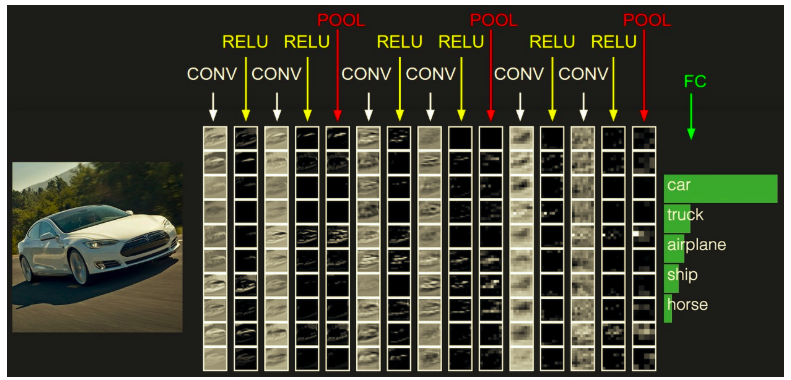
We stack a few CONV-RELU layers, follows them with pooling layers, and repeats this pattern until the image has been merged spatially to a small size. At some point, it is common to transition to fully-connected layers. The last fully-connected layer holds the output, such as the class scores.
4. Classic CNN Model
Now let's look at some classical CNN models
- LeNet-5: The oldest CNN
- AlexNet: Similar to LeNet but much bigger; and it started to use Relu
- VGG-16: use same 3x3 filter and same max pooling all the time
- ResNet: it skip the connection and create a shot cut: \[a^{[l+2]} = g(z^{[l+2]}+a^{[l]})\] so if \(w^{[l+2]}=0\) and \(b^{[l+2]}=0\) which means this layer doesn't learn any new things, then we still get \[a^{[l+2]}=g(a^{[l]})\] so it helps with vanishing and exploding gradient problems and then works well for deep NN.
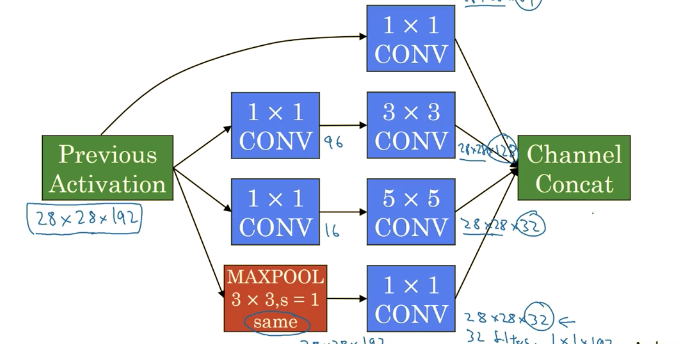
- Inception Net: Instead choosing what filter size you want use or even do you want a cone layer or pooling layer, it stacks them all in one layer. To minimize the number of parameters, they use 1x1 convolution (shrink the depth but keep the height and weight the same; Empirically, it will save time and not hurt performance):
Next article let's look at some real cases CNN has been used and try to implement it by hands-on examples.
Reference:
DeepLearning.ai
http://cs231n.github.io/convolutional-networks/